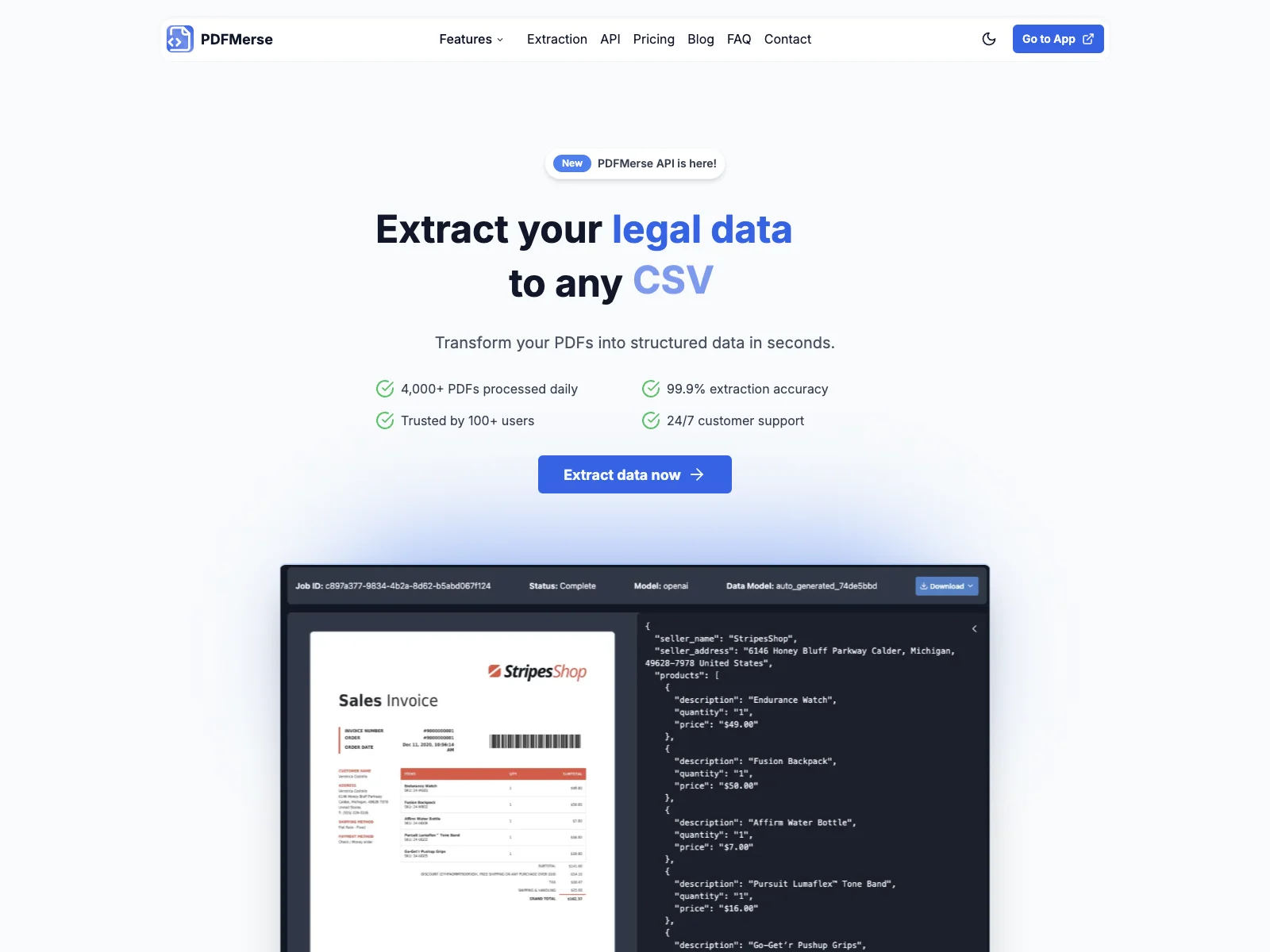
PDFMerse: Extraindo Dados de PDFs com Facilidade
PDFMerse é uma solução inovadora para a extração de dados de documentos PDF. Com tecnologia de inteligência artificial avançada, esta ferramenta revoluciona a forma como lidamos com informações em documentos.
Visão Geral: PDFMerse combina IA de ponta com processamento de dados robusto, oferecendo capacidades de extração de dados PDF incomparáveis. Ela pode lidar com vários tipos de PDFs, incluindo faturas, registros médicos e documentos legais.
Recursos Principais:
- Extração Automática de Dados: Elimina a entrada manual de dados, economizando horas de trabalho.
- Garantia de Dados Estruturados: Os dados extraídos estão sempre em um formato definido e estruturado, prontos para uso imediato em seus sistemas.
- Validação de Extração: Processos de validação internos garantem a precisão e integridade dos dados extraídos, minimizando erros e inconsistências.
- Suporte a Vários Idiomas: Permite a extração de dados de documentos em vários idiomas, expandindo a capacidade de processamento de informações globais.
- Suporte a Texto Escrito à Mão: A IA pode extrair dados de texto impresso e escrito à mão em PDFs.
Uso Básico: A integração do PDFMerse é fácil. Sua API RESTful permite a integração direta das capacidades de extração de PDFs em suas aplicações. Com solicitações HTTP simples, é possível extrair dados de PDFs e receber os resultados em formato JSON garantido. Além disso, a ferramenta oferece opções de preços flexíveis, atendendo às necessidades de indivíduos, pequenas equipes e grandes organizações.