AudioCraft: Uma Solução Avançada para Áudio Gerativo
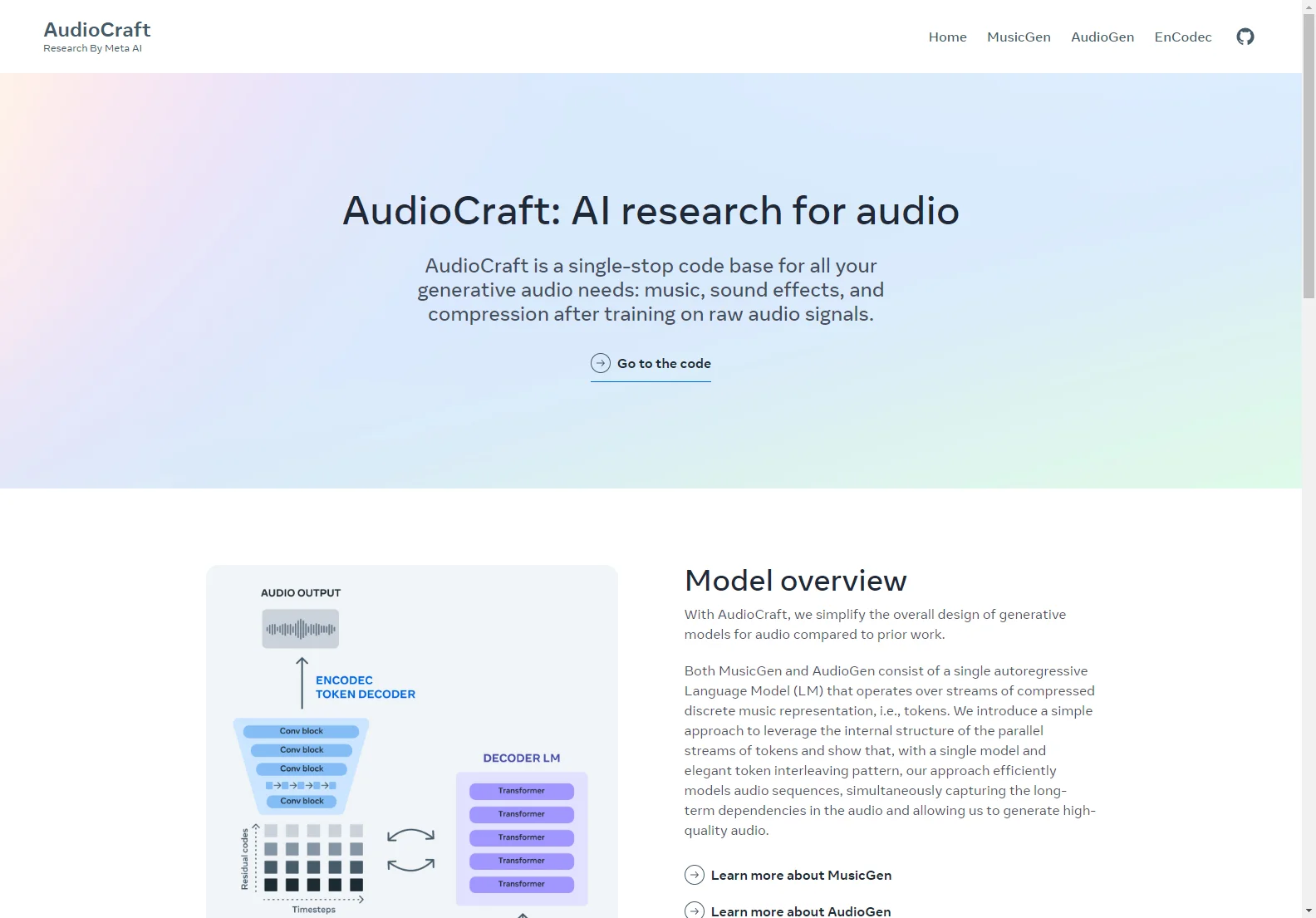
AudioCraft é uma base de código única que abrange todas as suas necessidades de áudio gerativo, incluindo música, efeitos sonoros e compressão, após treinamento em sinais de áudio bruto. Com o AudioCraft, simplificamos o design geral dos modelos gerativos de áudio em comparação com trabalhos anteriores. Ambos os modelos MusicGen e AudioGen consistem em um único Modelo de Linguagem Autorregressivo (LM) que opera sobre fluxos de representação de música discreta comprimida, ou seja, tokens. Introduzimos uma abordagem simples para aproveitar a estrutura interna dos fluxos paralelos de tokens e mostramos que, com um único modelo e um padrão elegante de intercalamento de tokens, nossa abordagem modela eficientemente sequências de áudio, capturando simultaneamente as dependências de longo prazo no áudio e permitindo gerar áudio de alta qualidade. Nossos modelos aproveitam o EnCodec, um codec neural de áudio, para aprender os tokens de áudio discretos a partir da forma de onda bruta. O EnCodec mapeia o sinal de áudio para um ou vários fluxos paralelos de tokens discretos. Em seguida, usamos um único modelo de linguagem autorregressivo para modelar recursivamente os tokens de áudio do EnCodec. Os tokens gerados são então fornecidos ao decodificador do EnCodec para mapeá-los de volta ao espaço de áudio e obter a forma de onda de saída. Finalmente, diferentes tipos de modelos de condicionamento podem ser usados para controlar a geração, como o uso de um codificador de texto pré-treinado para aplicações de texto para áudio. O AudioGen se concentra na geração de texto para som e aprendeu a produzir áudio a partir de sons ambientais. Já o MusicGen produz amostras de música diversificadas e longas a partir de entradas de texto fornecidas pelo usuário.