AudioCraft : Un code base pour l'audio génératif
AudioCraft est une solution unique pour toutes vos exigences en matière d'audio génératif, que ce soit pour la musique, les effets sonores ou la compression après l'entraînement sur des signaux audio bruts.
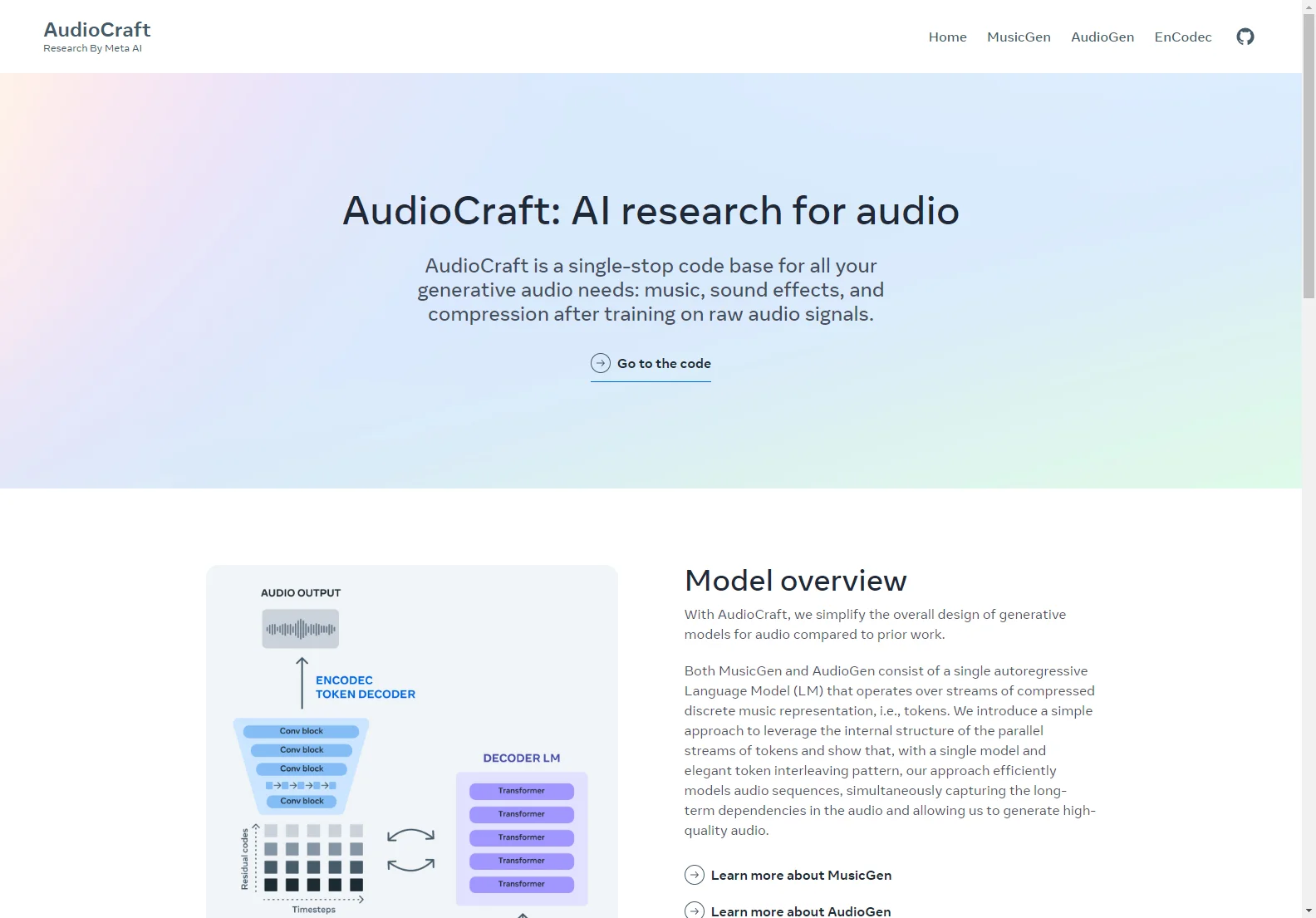
La conception globale des modèles génératifs pour l'audio est simplifiée avec AudioCraft par rapport aux travaux antérieurs. MusicGen et AudioGen consistent en un seul modèle Language Model (LM) autorégressif qui opère sur des flux de représentation musicale discrète compressée, c'est-à-dire des jetons. Nous introduisons une approche simple pour tirer parti de la structure interne des flux parallèles de jetons et montrons que, avec un seul modèle et un motif d'entrelacement de jetons élégant, notre approche modélise efficacement les séquences audio, capturant simultanément les dépendances à long terme dans l'audio et nous permettant de générer un audio de haute qualité.
Nos modèles tirent parti de l'Encodec neural audio codec pour apprendre les jetons audio discrets à partir de la forme d'onde audio brute. EnCodec mappe le signal audio vers un ou plusieurs flux parallèles de jetons discrets. Nous utilisons ensuite un seul modèle Language Model autorégressif pour modéliser de manière récursive les jetons audio provenant d'EnCodec. Les jetons générés sont ensuite envoyés au décodeur d'EnCodec pour les mapper de nouveau vers l'espace audio et obtenir la forme d'onde de sortie. Enfin, différents types de modèles de conditionnement peuvent être utilisés pour contrôler la génération, par exemple en utilisant un encodeur de texte pré-entraîné pour des applications de texte-à-audio.
AudioGen est axé sur la génération de texte-à-son et a appris à produire de l'audio à partir de sons environnementaux. MusicGen, quant à lui, produit des échantillons de musique variés et longs à partir d'entrées de texte fournies par l'utilisateur.