Twelve Labs: Die Zukunft der Video-Verständigung
Twelve Labs bringt eine bahnbrechende Multimodale KI auf den Markt, die die Verständigung von Videos auf eine neue Ebene hebt. Diese KI versteht Videos in einer Weise, die an die menschliche Wahrnehmung erinnert.
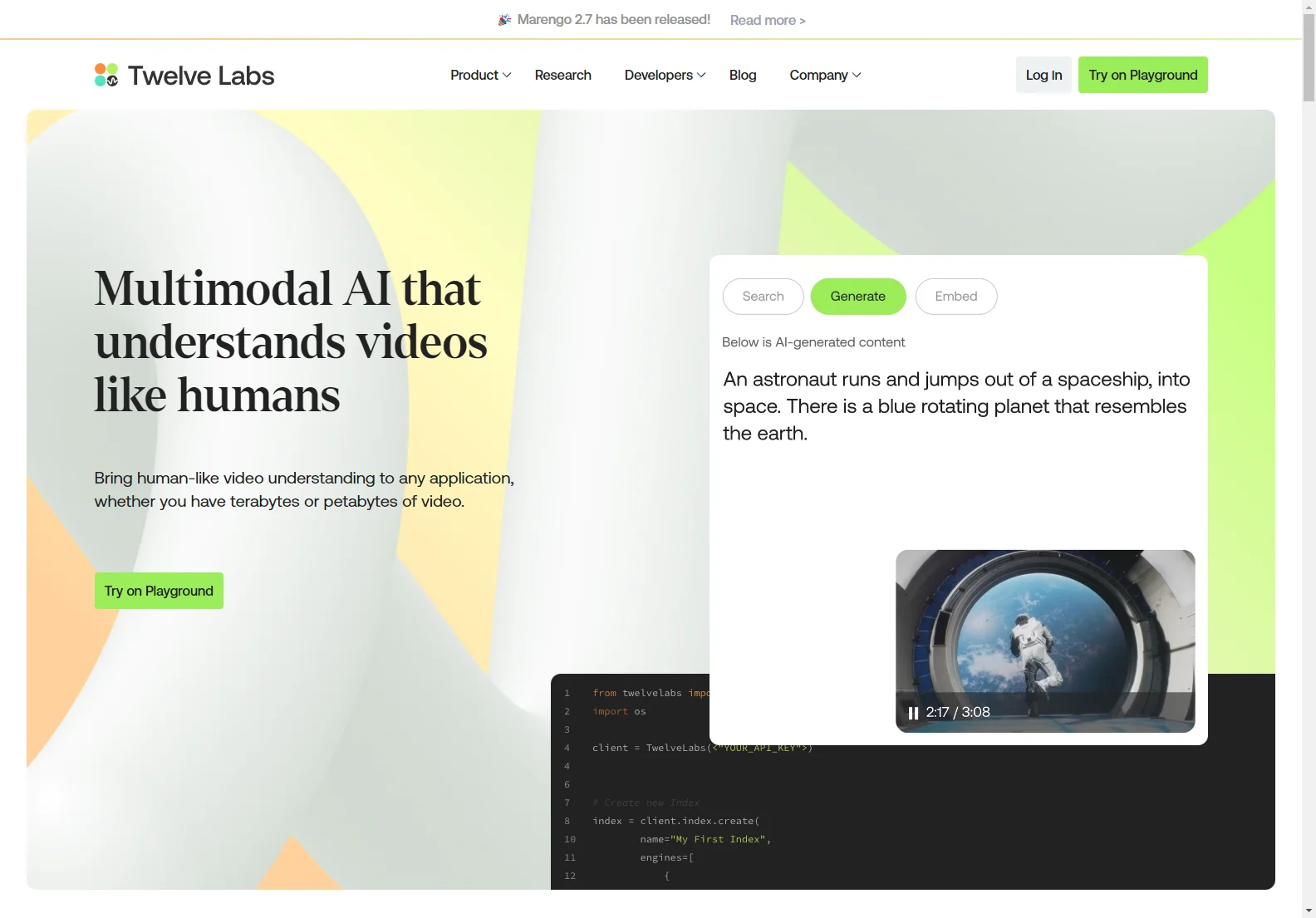
Kernfunktionen: Die Technologie ermöglicht es, in riesigen Video-Bibliotheken genau die Momente zu finden, die man sucht. Man kann mittels natürlicher Sprache Szenen lokalisieren. Zudem kann man durch Prompting genaues und aufschlussreiches Textmaterial über Videos generieren, seien es Zusammenfassungen, detaillierte Berichte, Titelvorschläge oder andere relevante Informationen.
Grundlegende Nutzung: Die Nutzung ist einfach und intuitiv. Man kann die Technologie in verschiedenen Anwendungen einsetzen, um die Video-Verarbeitung zu optimieren. Beispielsweise kann man damit die Suche in Videos verbessern, relevante Texte generieren und sogar multimodale Einbettungen erstellen.
Twelve Labs setzt auf modernste Video-Grundlagenmodelle, die reichhaltige Video-Einbettungen erstellen. Diese Modelle bilden die Grundlage für Aufgaben wie Suche, Generierung und Einbettung und sorgen für eine hohe Qualität und Genauigkeit in der Video-Verarbeitung.