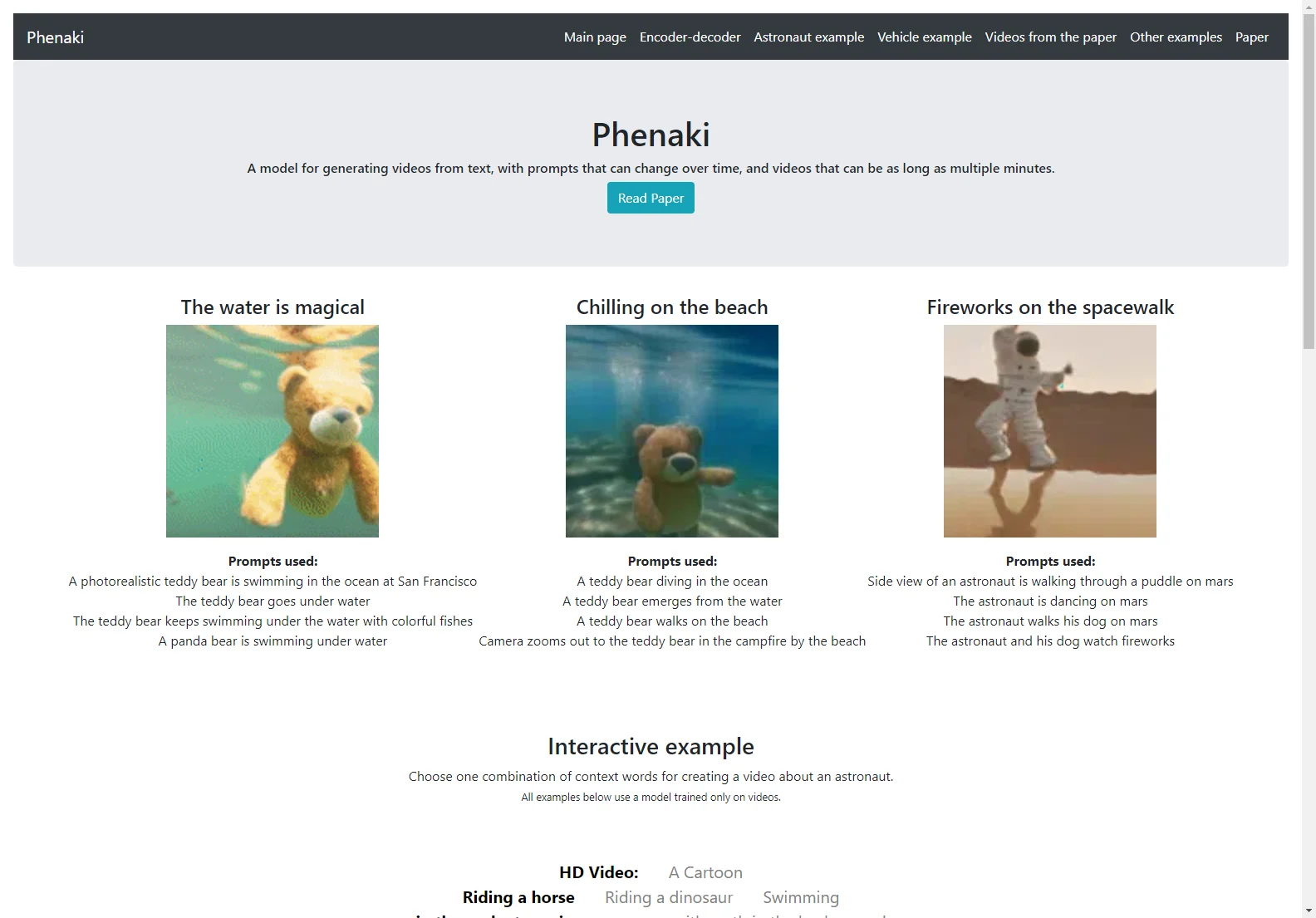
Phenaki: Ein bahnbrechendes Modell für die Videogenerierung
Phenaki ist eine beeindruckende Entwicklung in der Welt der Videogenerierung. Dieses Modell hat die Fähigkeit, realistische Videos basierend auf einer Sequenz textueller Prompts zu erstellen. Die Herausforderung bei der Erzeugung von Videos aus Text liegt in der hohen Rechenleistung, der begrenzten Menge an hochwertigen Text-Video-Daten und der variablen Länge der Videos. Phenaki löst diese Probleme, indem es ein neues kausales Modell für das Lernen von Videorepräsentationen einführt, das das Video in eine kleine Darstellung diskreter Token komprimiert. Dieser Tokenizer verwendet kausale Aufmerksamkeit in der Zeit, wodurch er mit Videos unterschiedlicher Länge arbeiten kann.
Um Video-Token aus Text zu generieren, wird ein bidirektionaler maskierter Transformer verwendet, der an vorberechneten Text-Token bedingt ist. Die erzeugten Video-Token werden anschließend de-tokenisiert, um das tatsächliche Video zu erstellen. Um Datenprobleme zu lösen, wird gezeigt, wie das gemeinsame Training an einem großen Korpus von Bild-Text-Paaren sowie einer kleineren Anzahl von Video-Text-Beispielen zu einer Verallgemeinerung führen kann, die über das hinausgeht, was in den Video-Datasets verfügbar ist.
Im Vergleich zu früheren Videogenerierungsmethoden kann Phenaki beliebig lange Videos basierend auf einer Sequenz von Prompts (z. B. zeitvariablen Text oder einer Geschichte) in einem offenen Bereich generieren. Dies ist, soweit wir wissen, das erste Mal, dass ein Papier die Generierung von Videos aus zeitvariablen Prompts untersucht. Darüber hinaus übertrifft der vorgeschlagene Video-Encoder-Decoder alle derzeit in der Literatur verwendeten Frame-basierten Baselines in Bezug auf die raum-zeitliche Qualität und die Anzahl der Token pro Video.