AudioCraft - Die Zukunft der generativen Audiotechnologie
AudioCraft ist eine bahnbrechende Entwicklung in der Welt der Audiotechnologie. Es vereinfacht das Design generativer Modelle für Audio im Vergleich zu früheren Arbeiten.
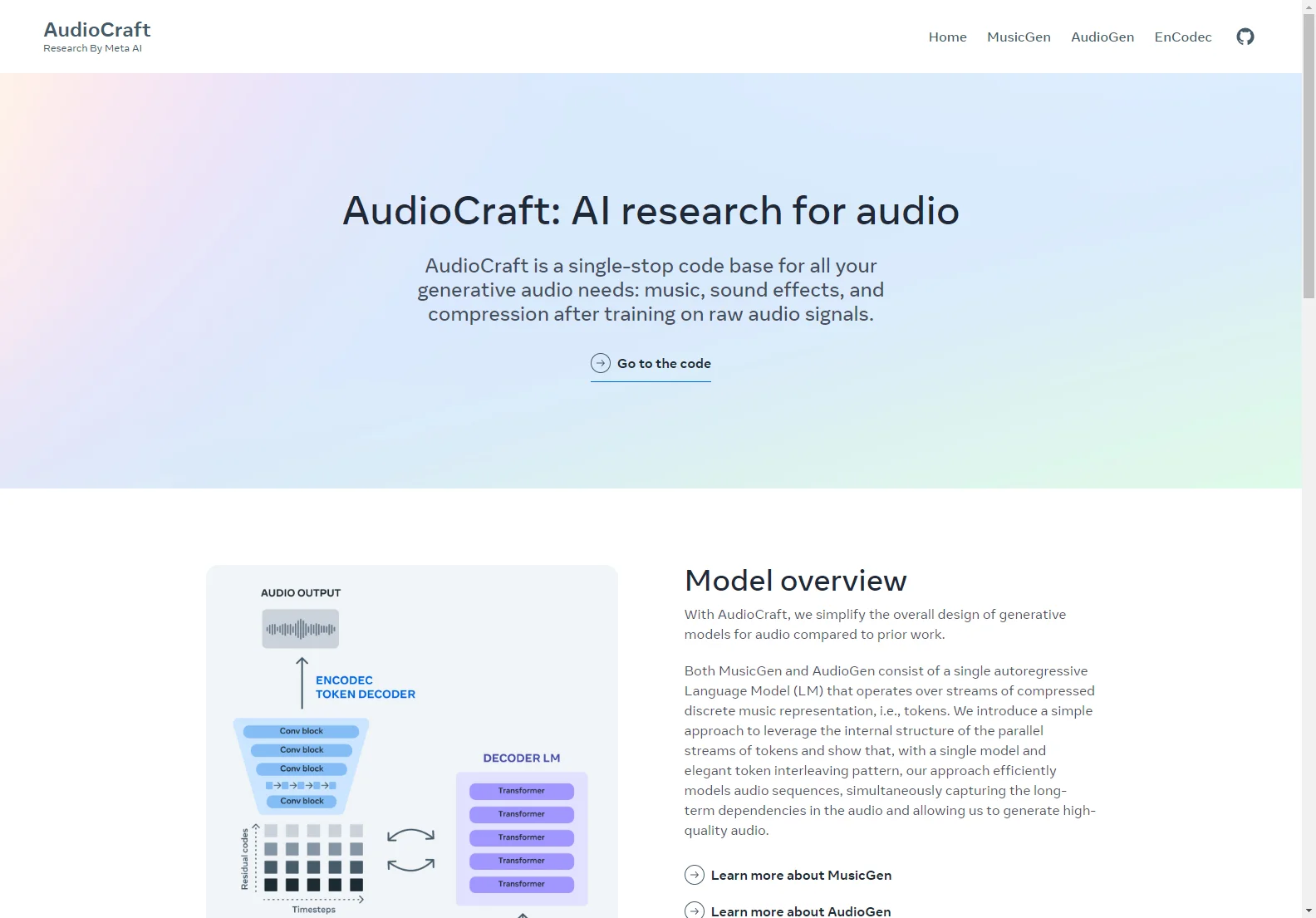
Die Modelle wie MusicGen und AudioGen bestehen aus einem einzigen autoregressiven Language Model (LM), das über Ströme komprimierter diskreter Musikrepräsentationen, also Token, arbeitet. Mit einer einfachen Methode nutzen wir die interne Struktur der parallelen Tokenströme und zeigen, dass unser Ansatz mit einem einzigen Modell und einem eleganten Token-Interleaving-Muster Audio-Sequenzen effizient modelliert. Dadurch können wir hochwertige Audio erzeugen und gleichzeitig die langfristigen Abhängigkeiten im Audio erfassen.
Unsere Modelle nutzen den EnCodec-Neural-Audio-Codec, um die diskreten Audio-Token aus dem Roh-Audiosignal zu lernen. EnCodec bildet das Audiosignal in einen oder mehrere parallele Ströme diskreter Token ab. Anschließend verwenden wir ein einzelnes autoregressives Language Model, um die Audio-Token aus EnCodec rekursiv zu modellieren. Die erzeugten Token werden dann an den EnCodec-Decoder übergeben, um sie zurück in den Audio-Raum zu bringen und die Ausgangswellenform zu erhalten. Schließlich können verschiedene Arten von Konditionierungsmodellen verwendet werden, um die Generierung zu steuern, wie z.B. die Verwendung eines vortrainierten Text-Encoders für Text-to-Audio-Anwendungen.
AudioGen konzentriert sich auf die Text-to-Sound-Generierung und hat gelernt, Audio aus Umweltgeräuschen zu produzieren. MusicGen hingegen erzeugt vielfältige und lange Musikbeispiele aus Textinputs der Benutzer. Hören Sie sich die Samples an und entdecken Sie die Möglichkeiten von AudioCraft!