Mais Eficiente Pré-Treinamento de Modelo NLP com ELECTRA
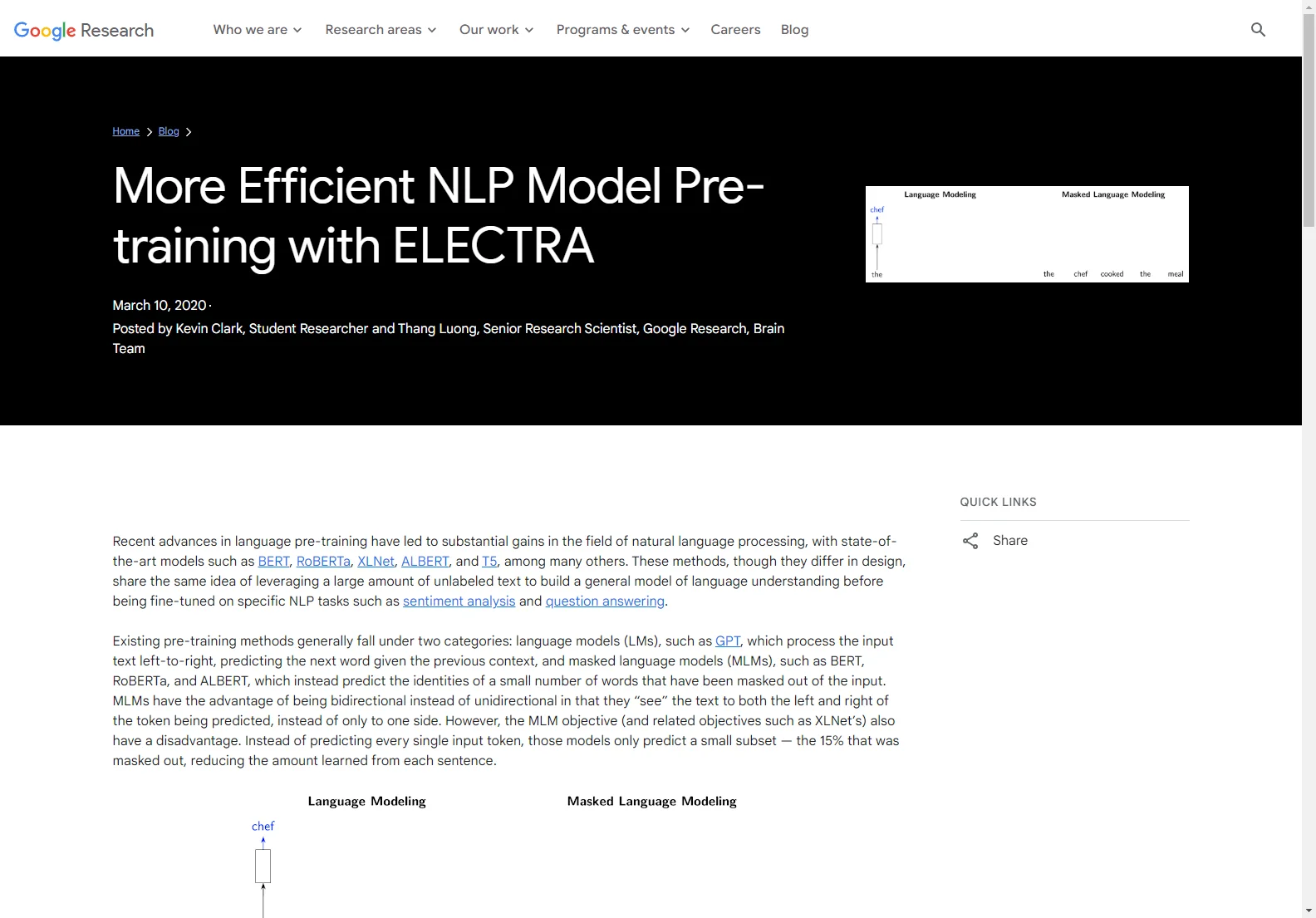
Os avanços recentes no pré-treinamento de linguagem trouxeram ganhos substanciais no campo do processamento de linguagem natural. Modelos de ponta, como BERT, RoBERTa, XLNet, ALBERT e T5, compartilham a ideia de aproveitar uma grande quantidade de texto não rotulado para construir um modelo geral de compreensão de linguagem antes de serem ajustados para tarefas específicas de NLP, como análise de sentimentos e resposta a perguntas.
No entanto, os métodos de pré-treinamento existentes têm desvantagens. Os modelos de linguagem mascarada (MLMs), como BERT, RoBERTa e ALBERT, prevêem apenas um pequeno subconjunto de palavras mascaradas do texto de entrada.
ELECTRA, ou Efficiently Learning an Encoder that Classifies Token Replacements Accurately, é um novo método de pré-treinamento que supera as técnicas existentes com o mesmo orçamento computacional. Ele usa uma tarefa de pré-treinamento chamada detecção de token substituído (RTD), que treina um modelo bidirecional enquanto aprende de todas as posições de entrada.
A tarefa de pré-treinamento requer que o modelo determine quais tokens do texto original foram substituídos ou mantidos. Isso resulta em uma aprendizagem de representação poderosa, pois o modelo precisa aprender uma representação precisa da distribuição de dados para resolver a tarefa.
Nós comparamos ELECTRA contra outros modelos NLP de ponta e descobrimos que ele melhora substancialmente sobre os métodos anteriores, com o mesmo orçamento computacional. Além disso, um modelo ELECTRA pequeno pode ser treinado com boa precisão em uma única GPU em 4 dias.
Estamos liberando o código para o pré-treinamento de ELECTRA e seu ajuste para tarefas downstream, bem como pesos pré-treinados para ELECTRA-Large, ELECTRA-Base e ELECTRA-Small. Atualmente, os modelos ELECTRA são apenas em inglês, mas esperamos liberar modelos pré-treinados em várias línguas no futuro.