CM3leon: Um Modelo Gerativo Multimodal Avançado
CM3leon é um modelo gerativo inovador que combina a capacidade de gerar texto e imagens. Ele é treinado com uma receita adaptada de modelos de linguagem baseados apenas em texto, incluindo uma fase de pré-treinamento aumentado por recuperação em larga escala e uma segunda fase de ajuste fino supervisionado multitarefa (SFT).
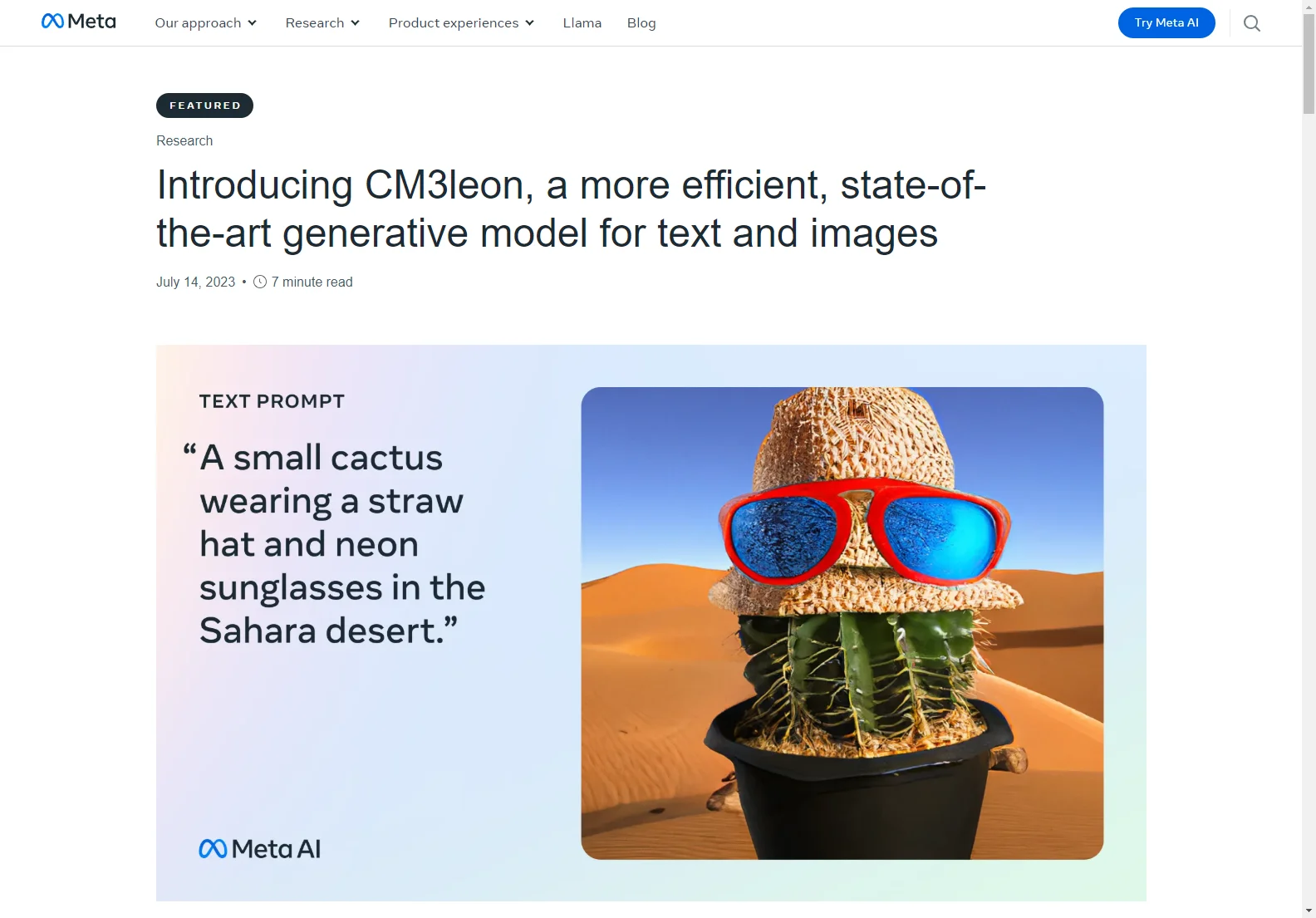
Este modelo alcança um desempenho de ponta na geração de texto para imagem, mesmo sendo treinado com cinco vezes menos computação do que métodos anteriores baseados em transformadores. Ele possui a versatilidade e eficácia dos modelos autoregressivos, mantendo baixos custos de treinamento e eficiência de inferência.
CM3leon pode gerar sequências de texto e imagens condicionadas a sequências arbitrárias de outros conteúdos de imagem e texto, expandindo a funcionalidade dos modelos anteriores. Ele também é submetido a um ajuste de instrução em larga escala para a geração de imagem e texto, melhorando significativamente o desempenho em tarefas como geração de legendas de imagem, resposta a perguntas visuais, edição baseada em texto e geração de imagem condicional.
Nas tarefas de geração de imagem guiada por texto e edição, CM3leon se destaca, conseguindo lidar com objetos complexos e promessas que incluem muitas restrições. Ele também pode seguir uma variedade de prompts diferentes para gerar legendas curtas ou longas e responder perguntas sobre uma imagem.
A arquitetura do CM3Leon utiliza um transformador apenas decodificador, semelhante aos modelos baseados em texto bem estabelecidos, mas com a capacidade de lidar com texto e imagens. O treinamento do CM3leon é aumentado por recuperação, melhorando a eficiência e a controlabilidade do modelo resultante.
Com o avanço contínuo da indústria de IA, modelos gerativos como o CM3leon estão se tornando cada vez mais sofisticados. Embora ainda haja desafios a serem enfrentados, como a questão de vieses nos dados de treinamento, acreditamos que a transparência será fundamental para acelerar o progresso.