Phenaki : Un Modèle de Génération de Vidéos à partir de Textes
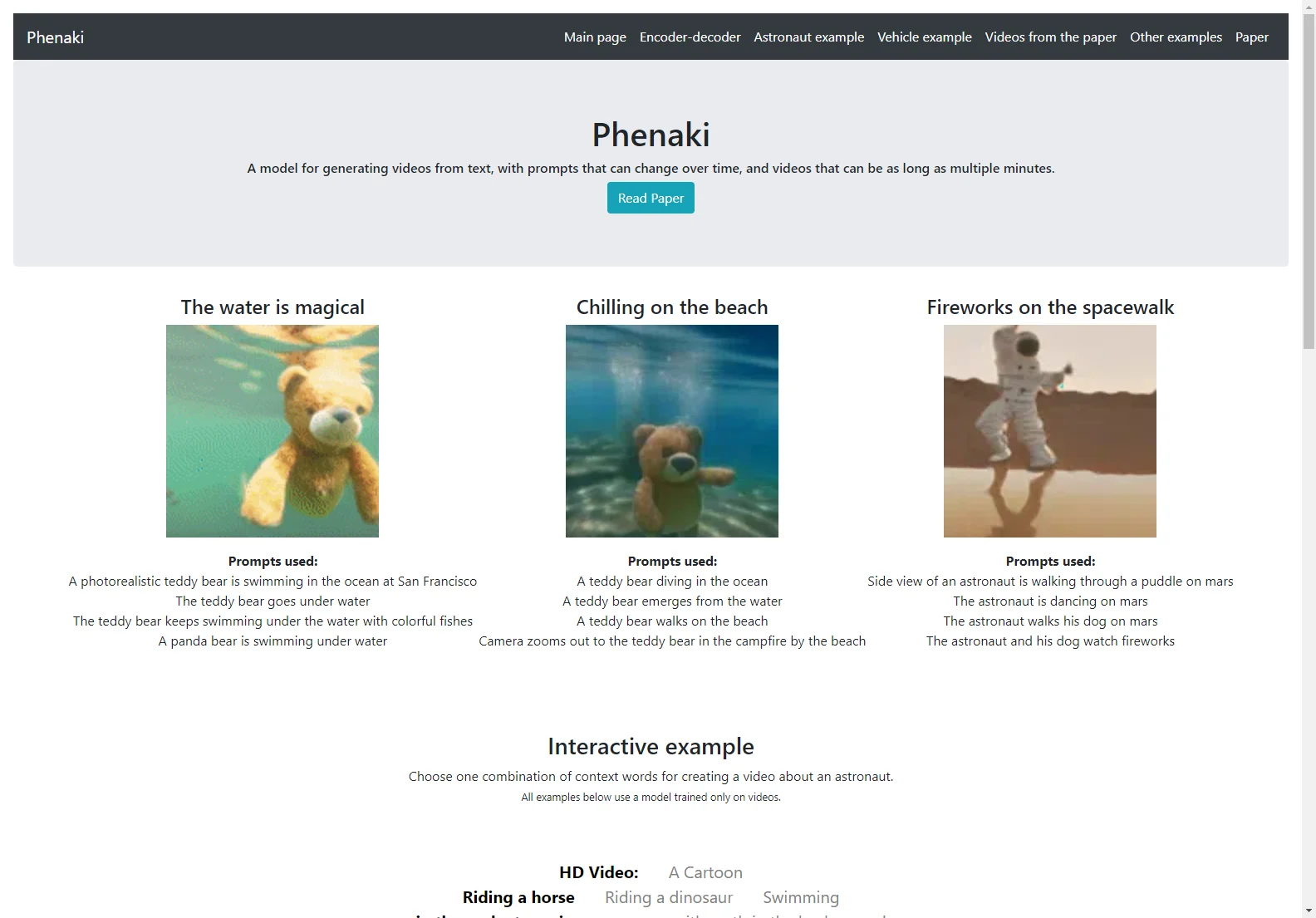
Phenaki est un modèle innovant capable de créer des vidéos réalistes en fonction d'une séquence de prompts textuels. La génération de vidéos à partir de textes représente un défi considérable en raison du coût informatique, du nombre limité de données de haute qualité textes-vidéos et de la longueur variable des vidéos.
Pour résoudre ces problèmes, Phenaki introduit un nouveau modèle causal pour l'apprentissage de la représentation vidéo. Ce modèle compresse la vidéo en une petite représentation de jetons discrets. Le tokenizer utilise une attention causale dans le temps, ce qui lui permet de fonctionner avec des vidéos de longueur variable.
Pour générer des jetons vidéo à partir de textes, un transformateur masqué bidirectionnel conditionné sur des jetons de texte pré-calculés est utilisé. Les jetons vidéo générés sont ensuite dé-tokenisés pour créer la vidéo réelle.
En ce qui concerne les problèmes de données, il est démontré comment l'entraînement conjoint sur un grand corpus de paires image-texte ainsi que sur un plus petit nombre d'exemples vidéo-texte peut entraîner une généralisation au-delà de ce qui est disponible dans les ensembles de données vidéo.
Comparé aux méthodes de génération de vidéos précédentes, Phenaki peut générer des vidéos de longueur arbitraire conditionnées par une séquence de prompts (c'est-à-dire du texte variable dans le temps ou une histoire) dans un domaine ouvert.
À notre connaissance, c'est la première fois qu'un article étudie la génération de vidéos à partir de prompts variables dans le temps. De plus, l'encodeur-décodeur vidéo proposé surpasse toutes les bases de référence par trame actuellement utilisées dans la littérature en termes de qualité spatio-temporelle et du nombre de jetons par vidéo.