Un modèle de pré-entraînement NLP révolutionnaire : ELECTRA
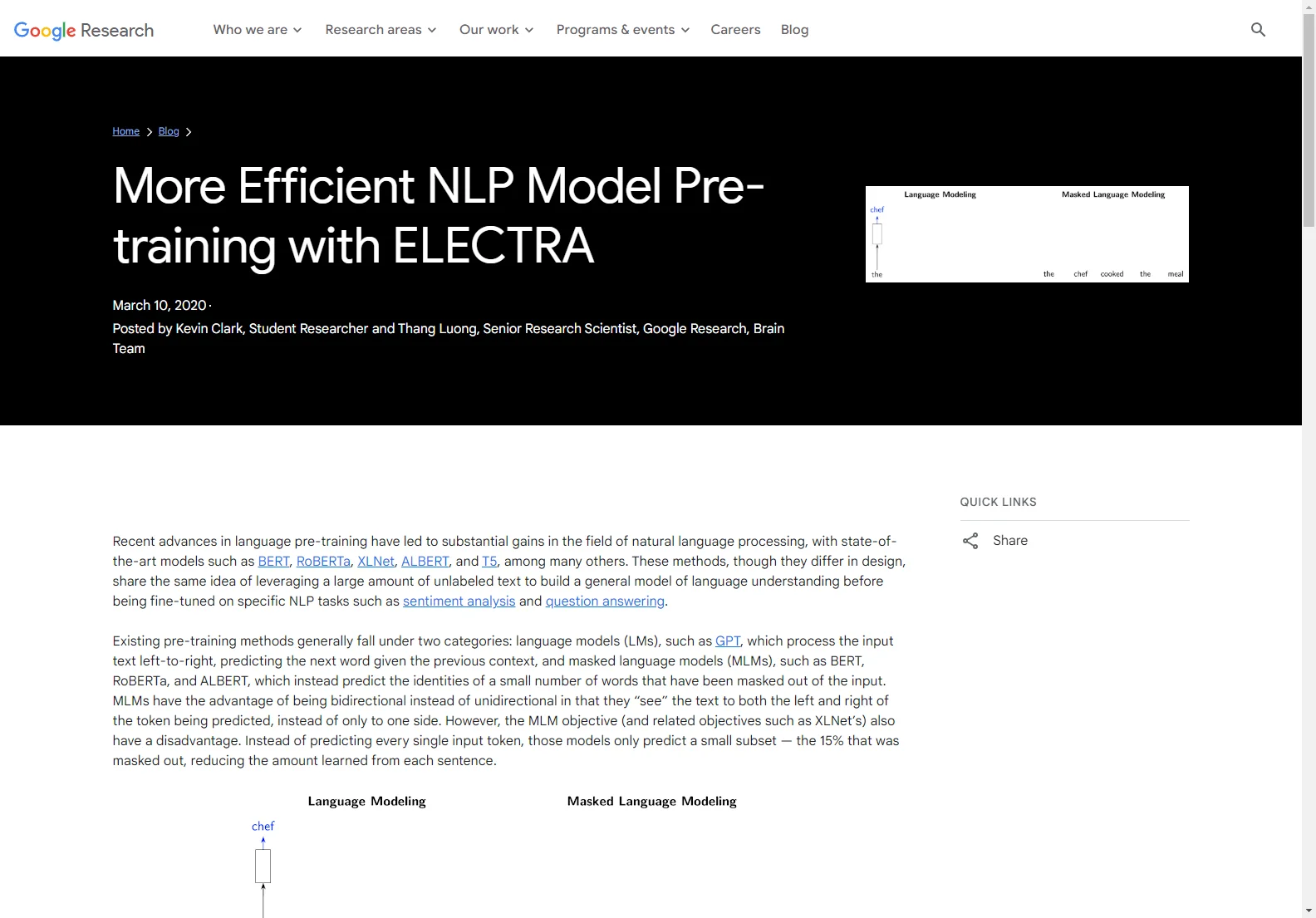
Dans le domaine du pré-entraînement NLP, les méthodes existantes ont leurs limites. Les modèles de langage comme GPT traitent le texte de gauche à droite, tandis que les modèles de langage masqué comme BERT ne prédisent qu'un petit sous-ensemble de mots masqués. ELECTRA, quant à lui, opte pour une approche différente. Il utilise une tâche de détection de jetons remplacés (RTD) inspirée des réseaux adversariaux génératifs. Au lieu de masquer les jetons comme chez BERT, ELECTRA altère l'entrée en remplaçant certains jetons par des faux plausibles mais incorrects. Le modèle, en tant que discriminateur, doit déterminer quels jetons ont été remplacés. Cette tâche de classification binaire est appliquée à chaque jeton d'entrée, ce qui le rend plus efficace que le MLM. Le générateur, un petit modèle de langage masqué, est entraîné conjointement avec le discriminateur. Après le pré-entraînement, le générateur est éliminé et le discriminateur est ajusté finement pour des tâches en aval. ELECTRA a montré des résultats exceptionnels, surpassant les méthodes précédentes avec le même budget de calcul. Il peut être entraîné sur un seul GPU avec une bonne précision et atteint des résultats de pointe sur des benchmarks tels que SQuAD et GLUE. Le code pour l'entraînement préalable et l'ajustement fin de ELECTRA est mis à disposition, ainsi que des poids pré-entraînés.