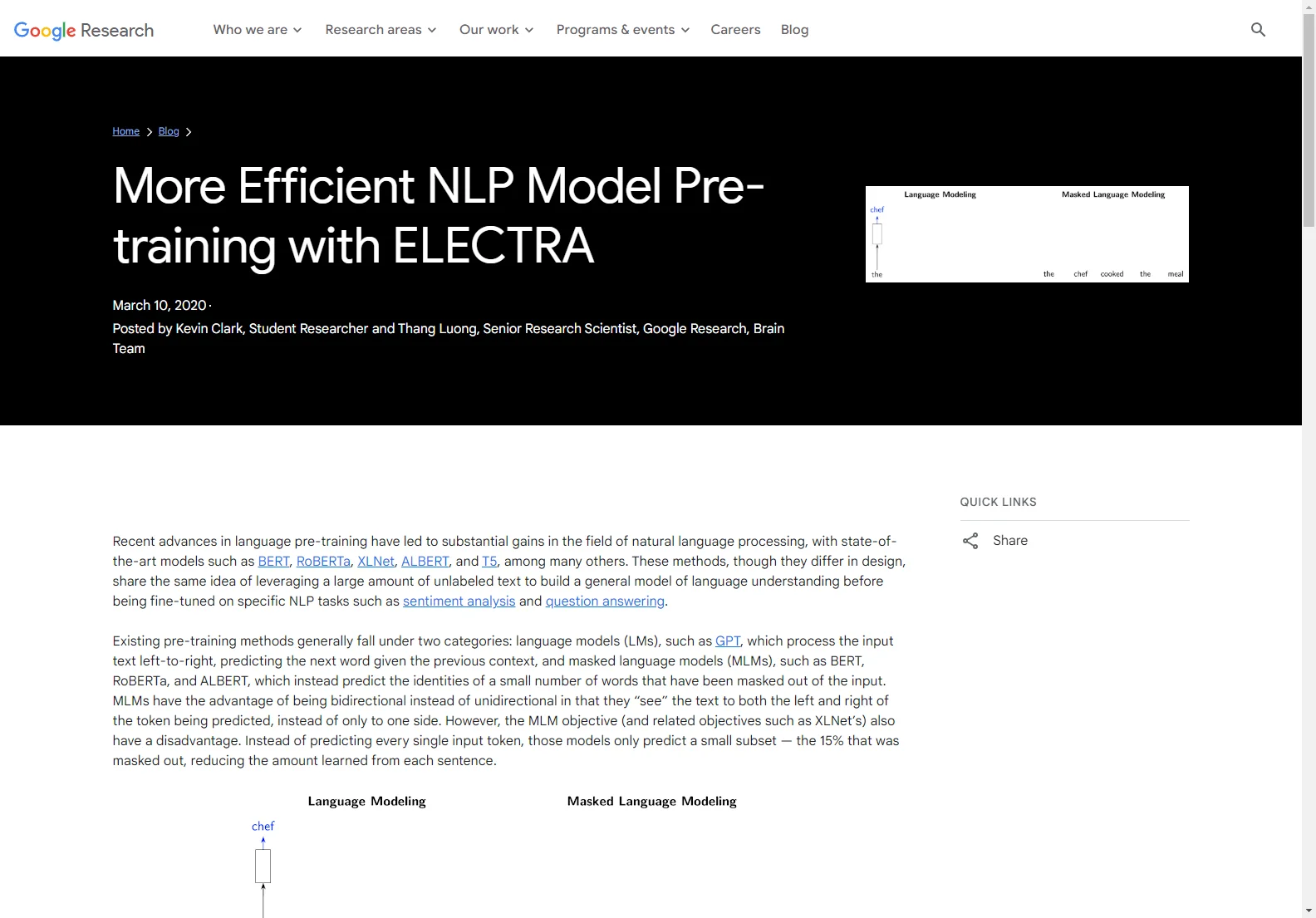
ELECTRA: Die coole Lösung für effizientere NLP-Vorausbildung
ELECTRA bringt frischen Wind in die Welt der Sprachvorausbildung. Während andere Methoden ihre Schwächen haben, trumpft ELECTRA auf. Hier kommt die coole Sache: Es nutzt eine neue Aufgabe namens 'replaced token detection' (RTD). Statt wie bei BERT Tokens mit '[MASK]' zu ersetzen, werden einige Eingabetokens mit zwar sinnvoll erscheinenden, aber falschen Tokens getauscht. Und jetzt kommt der Clou: Das Modell, der 'Discriminator', muss rausfinden, welche Tokens aus der ursprünglichen Eingabe ersetzt wurden und welche gleich geblieben sind. Und das gilt für jeden einzelnen Eingabetoken! Das macht die Sache richtig effizient.
Die Vorverarbeitung mit ELECTRA ist der Burner! Das Modell muss eine präzise Darstellung der Datenverteilung lernen, um die Aufgabe zu meistern. Die Ergebnisse sind der Wahnsinn! ELECTRA haut andere state-of-the-art NLP-Modelle aus den Socken. Mit weniger Rechenpower erreicht es Leistungen, die mit denen von RoBERTa und XLNet mithalten können. Außerdem kann man ein kleines ELECTRA-Modell in ein paar Tagen auf einer einzigen GPU trainieren und dabei eine ordentliche Genauigkeit erreichen.
Der Code für die Vor- und Nachverarbeitung von ELECTRA wird veröffentlicht, zusammen mit vorausgebildeten Gewichten für verschiedene Modelle. Momentan ist ELECTRA zwar nur für Englisch da, aber man hofft, in Zukunft auch Modelle für mehrere Sprachen rauszubringen.